Routing
Published:
This post covers MOBILE AD HOC NETWORKING by STEFANO BASAGNI.
Basic Ideas
Routing in wireless networks has become an interesting topic.
These protocols cover a wide range of design choices and approaches, from simple modifications of Internet protocols, to more complex multilevel hierarchical schemes.
Many of these routing protocols have been designed based on similar sets of assumptions.
For instance, most routing protocols assume that all nodes have homogeneous resources
and capabilities.
This includes the transmission ranges of the nodes. Also, bidirectional links are often assumed. In some instances, protocols have mechanisms for determining whether links are bidirectional.
In these cases, the protocols will then eliminate unidirectional links from consideration for routing. In other instances, protocols can actually utilize these unidirectional links, whereas other protocols simply assume all links are bidirectional.
Finally, although the ultimate end goal of a protocol may be operation in large networks, most protocols are typically designed for moderately sized networks of 10 to 100 nodes.
Before describing the types of approaches and example protocols, it is important to explain the developmental goals for routing protocol so that the design choices of the protocols can be better understood.
Defining characteristics of ad hoc networks include resource-poor devices, limited bandwidth, high error rates, and a continually changing topology. Among the available resources, battery power is typically the most constraining.
Hence, the following are typical design goals for ad hoc network routing protocols:
The Mobile Ad Hoc Network - Fundamental System Design
- design goals for ad hoc network routing protocols:
- Minimal control overhead. Control messaging consumes bandwidth, processing resources, and battery power to both transmit and receive a message.
- Because bandwidth is at a premium, routing protocols should not send more than the minimum number of control messages they need for operation, and should be designed so that this number is relatively small.
- While transmitting is roughly twice as power consuming as receiving, both operations are still power consumers for the mobile devices. Hence, reducing control messaging also helps to conserve battery power.
- Minimal processing overhead. Algorithms that are computationally complex require significant processing cycles in devices. Because the processing cycles cause the mobile device to use resources, more battery power is consumed.
- Protocols that are lightweight and require a minimum of processing from the mobile device reserve battery power for more user-oriented tasks and extend the overall battery lifetime.
- Multihop routing capability. Because the wireless transmission range of mobile nodes is often limited, sources and destinations may typically not be within direct transmission range of each other. Hence, the routing protocol must be able to discover multihop routes between sources and destinations so that communication between those nodes is possible.
- Dynamic topology maintenance. Once a route is established, it is likely that some link in the route will break due to node movement. In order for a source to communicate with a destination, a viable routing path must be maintained, even while the intermediate nodes, or even the source or destination nodes, are moving.
- Further, because link breaks on ad hoc networks are common, link breaks must be handled quickly with a minimum of associated overhead.
- Loop prevention. Routing loops occur when some node along a path selects a next hop to the destination is also a node that occurred earlier in the path. When a routing loop exists, data and control packets may traverse the path multiple times until either the path is fixed and the loop is eliminated, or until the time to live (TTL) of the packet reaches zero.
- Because bandwidth is scarce and packet processing and forwarding is expensive, routing loops are extremely wasteful of resources and are detrimental to the network.
- Even a transitory routing loop will have a negative impact on the network. Hence, loops should be avoided at all times.
- With these goals in mind, numerous routing protocols have been developed for ad hoc networks.
- This topic describes the characteristics of classes of routing approaches, and then describes the operation of particular routing protocols within those classes.
- The routing protocols that are described are selected for a number of reasons.
- They may be popular choices for routing-related research among the ad hoc community; they may, at the time of this writing, be under consideration by the Mobile Ad Hoc Networks (MANET) Working Group of the IETF for standardization; or, they may simply be good, illustrative examples of their particular class of protocol.
PROACTIVE APPROACHES
The proactive routing approaches designed for ad hoc networks are derived from the traditional distance vector and link state protocols developed for use in the wireline Internet.
The primary characteristic of proactive approaches is that each node in the network maintains a route to every other node in the network at all times.
Route creation and maintenance is accomplished through some combination of periodic and event-triggered routing updates.
Periodic updates consist of routing information exchanges between nodes at set time intervals.
The updates occur at specific intervals, regardless of the mobility and traffic characteristics of the network.
Event-triggered updates, on the other hand, are transmitted whenever some event, such as a link addition or removal, occurs.
The mobility rate directly impacts the frequency of event-triggered updates because link changes are more likely to occur as mobility increases.
Proactive approaches have the advantage that routes are available the moment they are needed.
Because each node consistently maintains an up-to-date route to every other node in the network, a source can simply check its routing table when it has data packets to send to some destination and begin packet transmission.
However, the primary disadvantage of these protocols is that the control overhead can be significant in large networks or in networks with rapidly moving nodes.
Further, the amount of routing state maintained at each node scales as O(n), where n is the number of nodes in the network.
Proactive protocols tend to perform well in networks where there is a significant number of data sessions within the network.
In these networks, the overhead of maintaining each of the paths is justified because many of these paths are utilized.
Destination-Sequenced Distance Vector Routing
The Destination-Sequenced Distance Vector (DSDV) routing protocol is a distance vector protocol that implements a number of customizations to make its operation more suitable for ad hoc mobile networks.
DSDV utilizes per-node sequence numbers to avoid the counting to infinity problem common in many distance vector protocols.
A node increments its sequence number whenever there is a change in its local neighborhood (i.e., a link addition or removal).
When given a choice between two routes to a destination, a node always selects the route with the greatest destination sequence number.
This ensures utilization of the most recent information.
Because DSDV is a proactive protocol, each node maintains a route to every other node in the network. The routing table contains the following information for each entry: destination IP address, destination sequence number, next-hop IP address, hop count, and install time.
DSDV utilizes both periodic and event-triggered routing table updates. Every time interval, each node broadcasts to its neighbors its current sequence number, along with any routing table updates.
The routing table updates are of the form:
< destination IP address, destination sequence number, hopcount >
After receiving an update message, the neighboring nodes utilize this information to compute their routing table entries using an iterative distance vector approach.
In addition to periodic updates, DSDV also utilizes event-triggered updates to announce important link changes, such as link removals.
Such event-triggered updates ensure timely discovery of routing path changes.
As stated previously, if a node learns two distinct paths to a destination, the node selects the path with the greatest associated destination sequence number.
This ensures the utilization of the most recent routing information for that destination.
When given the choice between two paths with equal destination sequence numbers, the node selects the path with the shortest hop count.
On the other hand, if all metrics are equivalent, then the choice between routes is arbitrary. DSDV implements two primary optimizations to improve performance in mobile networks.
The first is that it defines two types of updates: full and incremental.
Full updates are transmissions of a node’s entire routing table. Because the size of these updates scales with the size of the network, these updates are performed relatively infrequently.
To reduce processing overhead and bandwidth consumption, incremental updates are transmitted more frequently. Incremental updates include only those routing table entries that have changed size since the last full update. Once the number of routing changes becomes too great to fit into a single NPDU, a full update is transmitted during the next update period.
Finally, DSDV also implements a mechanism to damp routing fluctuations. Due to the unsynchronized nature of the periodic updates, routing updates for a given destination can propagate along different paths at different rates.
To prevent a node from announcing a routing path change for a given destination while another, better, update for that destination is still en route, DSDV requires nodes to wait a settling time before announcing a new route with a higher metric for a destination.
The settling time is the average time to get all the updated advertisements for a route.
In this way, the node can be sure to receive all routing path changes for a destination before propagating any of those changes.
This reduces bandwidth utilization and power consumption by neighboring nodes.
REACTIVE APPROACHES
- Reactive routing techniques, also called on-demand routing, take a very different approach to routing than proactive protocols.
- A large percentage of the overhead from proactive protocols stems from the need for every node to maintain a route to every other node at all times.
- In a wired network, where connectivity patterns change relatively infrequently and resources are abundant, maintaining full connectivity graphs is a worthwhile expense.
- The benefit is that when a route is needed, it is immediately available. In an ad hoc network, however, link connectivity can change frequently and control overhead is costly.
- Because of these reasons, reactive routing approaches take a departure from traditional Internet routing approaches by not continuously maintaining a route between all pairs of network nodes.
- Instead, routes are only discovered when they are actually needed.
- When a source node needs to send data packets to some destination, it checks its route table to determine whether it has a route. If no route exists, it performs a route discovery procedure to find a path to the destination.
- Hence, route discovery becomes on-demand. If two nodes never need to talk to each other, then they do not need to utilize their resources maintaining a path between each other.
- The route discovery typically consists of the network-wide flooding of a request message.
- To reduce overhead, the search area may be reduced by a number of optimizations.
- The benefit of this approach is that signaling overhead is likely to be reduced compared to proactive approaches, particularly in networks with low to moderate traffic loads.
- When the number of data sessions in the network becomes high, then the overhead generated by the route discoveries approaches, and may even surpass, that of the proactive approaches.
- The drawback to reactive approaches is the introduction of a route acquisition latency.
- That is, when a route is needed by a source node, there is some finite latency while the route is discovered. In contrast, with a proactive approach, routes are typically available the moment they are needed. Hence, there is no delay to begin the data session.
- Ad Hoc On-Demand Distance Vector RoutingThe Ad Hoc On-Demand Distance Vector (AODV) Routing Protocol provides on-demand route discovery in mobile ad hoc networks.
- Like most reactive routing protocols, route finding is based on a route discovery cycle involving a broadcast network search and a unicast reply containing discovered paths. Similar to DSDV,
- AODV relies on per-node sequence numbers for loop freedom and for ensuring selection of the most recent routing path.
- AODV nodes maintain a route table in which next-hop routing information for destination nodes is stored.
- Each routing table entry has an associated lifetime value.
- If a route is not utilized within the lifetime period, the route is expired. Otherwise, each time the route is used, the lifetime period is updated so that the route is not prematurely deleted.
- When a source node has data packets to send to some destination, it first checks its route table to determine whether it already has a route to the destination. If such a route exists, it can use that route for data packet transmissions.
- Otherwise, it must initiate a route discovery procedure to find a route. To start route discovery, the source node creates a route request (RREQ) packet. It places in this packet the destination node’s IP address,
- the last known sequence number for that destination, and the source’s IP address and current sequence number.
- The RREQ also contains a hop count, initialized to zero, and a RREQ ID.
- The RREQ ID is a per-node, monotonically increasing counter that is incremented each time the node initiates a new RREQ.
- In this way, the source IP address, together with the RREQ ID, uniquely identifies a RREQ and can be used to detect duplicates.
- After creating this message, the source broadcasts the RREQ to its neighbors.
- When a neighboring node receives a RREQ, it first creates a reverse route to the source node.
- The node from which it received the RREQ is the next hop to the source node, and the hop count in the RREQ is incremented by one to get the hop distance from the source.
- The node then checks whether it has an unexpired route to the destination. If it does not have a valid route to the destination, it simply rebroadcasts the RREQ, with the incremented hop count value, to its neighbors.
- In this manner, the RREQ floods the network in search of a route to the destination.
- Below figure illustrates this flooding procedure. When a node receives a RREQ, it checks whether it has an unexpired route to the destination.
- If it does have such a route, then one other condition must hold for the node to generate a reply message indicating the route. The node’s route table entry for the destination must have a corresponding sequence number that is at least as great as the indicated destination sequence number in the route request. That is, dseqrt dseqRREQ
- When this condition holds, the node’s route table entry for the destination is at least as recent as the source node’s last known route to the destination.
- This condition ensures that the most recent route is selected, and also guarantees loop freedom.
- Once this condition is met, the node can create a route reply (RREP) message. The RREP contains the source node’s IP address, the destination node’s IP address, and the destination’s sequence number as given by the node’s route table entry for the destination.
- In addition, the hop count field in the RREP is set equal to the node’s distance from the destination.
- If the destination itself is creating the RREP, the hop count is set equal to zero.
- After creating the reply, the node unicasts the message to its next hop toward the source node.
- Thus, the reverse route that was created as the RREQ was forwarded is utilized to route the RREP back to the source node.
- When the next hop receives the RREP, it first creates a forward route entry for the destination node.
- It uses the node from which it received the RREP as the next hop toward th destination.
- The hop count for that route is the hop count in the RREP, incremented by one.
- This forward route entry for the destination will be utilized if the source selects this path for data packet transmissions to the destination. Once the node creates the forward route entry,
- it forwards the RREP to the destination node. The RREP is thus forwarded hop by hop to the source node, as indicated in below figure . Once the source receives the RREP, it can utilize the path for the transmission of data packets.
- If the source receives more than one RREP, it selects the route with the greatest sequence number and smallest hop count.
- Once a route is established, it must be maintained as long as it is needed.
- A route that has been recently utilized for the transmission of data packets is called an active route.
- Because of the mobility of the nodes, links along paths are likely to break. Breaks on links that are not being utilized for the transmission of data packets do not require any repair; however, breaks in active routes must be quickly repaired so that data packets are not dropped.
- When a link break along an active path occurs, the node upstream of the break (i.e., closer to the source node) invalidates the routes to each of those destinations in its route table. It then creates a route error (RERR) message.
- In this message it lists all of the destinations that are now unreachable due to the loss of the link. After creating the RERR message, it sends this message to its upstream neighbors that were also utilizing the link.
- These nodes, in turn, invalidate the broken routes and send their own RERR messages to their upstream neighbors that were utilizing the link.
- The RERR message thus traverses the reverse path to the source node, as illustrated in Figure 10.2(c).
- Once the source node receives the RERR, it can repair the route if the route is still needed.
- AODV contains a number of optimizations and optional features. To improve the protocol performance and reduce overhead, source nodes can utilize an expanding ring search to search for routes to the destination.
- The propagation of the RREQ is controlled by modifying the time to live (TTL) value of the packet. Incrementally larger areas of the network are searched until a route to the destination is discovered.
- If a route to the destination can be found in the local area, a network-wide flood can be avoided.
- Another optimization is the local repair of link breaks in active routes. When a link break occurs, instead of sending a RERR to the source, the node upstream of the break can try to repair the link locally itself.
- If successful, fewer data packets are dropped because the route is repaired more quickly. If the local repair attempt is unsuccessful, a RERR message is sent to the source node as previously described.
- In addition to these optimizations, AODV contains a number of optional features to improve operation in a wide range of scenarios. For instance, during route discovery, if only intermediate nodes respond and the destination never receives a copy of the RREQ, the destination will not necessarily have a route to the source node.
- If two-way conversation with the destination is desired, this lack of route from the destination to the source can be problematic.
- Hence, AODV defines a gratuitous RREP that can be sent to the destination node when a RREP is created by an intermediate node.
- This gratuitous RREP informs the destination of a route to the source, as if the destination had performed a route discovery.
- Another optional feature is the RREP acknowledgment (RREP-ACK). When unidirectional links are suspected, the RREP-ACK can be utilized to ensure the next hop received the RREP.
- If an RREP-ACK is not received, blacklists can be utilized to indicate unidirectional links so that these links are not used in future route discoveries. In addition, AODV allows the use of periodic Hello messages for monitoring connectivity to neighboring nodes.
Dynamic Source Routing
The Dynamic Source Routing (DSR) protocol [24] is similar to AODV in that it is a reactive routing protocol with a route discovery cycle for route finding. However, it has a few important differences.
One of the primary characteristics of DSR is that it is a source routing protocol; instead
of being forwarded hop by hop, data packets contain strict source routes that specify each node along the path to the destination.
Route request (RREQ) and route reply (RREP) packets accumulate source routes so that once a route is discovered, the source learns the entire source route and can place that route into subsequent data packets.
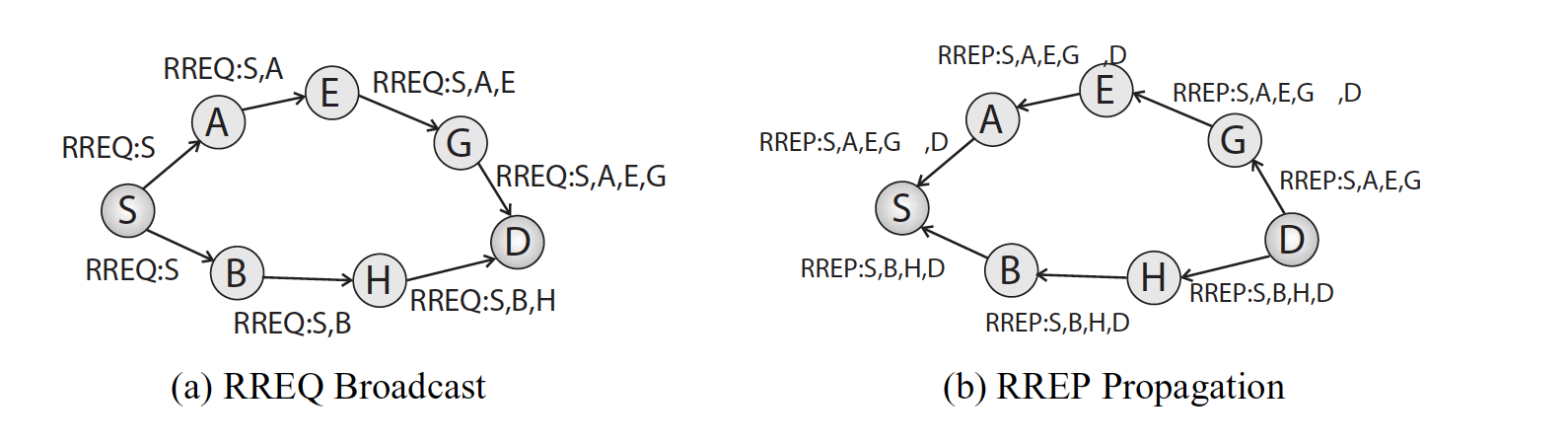
Below figure illustrates the process of route discovery. The source node places the destination IP address, as well as its own IP address, into the RREQ and then broadcasts the message to its neighbors.
When the neighboring nodes receive the message, they update their route to the source and then append their own IP addresses to the RREQ. Thus, as the RREQ is forwarded throughput the network, the traversed path is accumulated in the message.
When intermediate nodes receive the RREQ, they can create or update routing table entries for each of the nodes listed in the source route, not just the source node.
When a node with a route to the destination receives the RREQ, it responds by creating a RREP. If the node is the destination, it places the accumulated source route from the
RREQ into the RREP.
Otherwise, if the node is an intermediate node, it concatenates its source route to the destination to the accumulated route in the RREQ, and places this new route into the RREP.
Hence, in either scenario the message contains the full route between the source and the destination.
The source route in the RREP is reversed and the RREP is unicast to the source. Note that as intermediate nodes receive and process the RREP, they can create or update routing table entries to each of the nodes along the source route.
Below figure illustrates the propagation of two RREPs back to the source.
When a link break in an established path occurs, the node upstream of the break creates a route error (RERR) message and sends it to the source node.
Instead of maintaining a route table for tracking routing information, DSR utilizes a route cache.
The cache allows multiple route entries to be maintained per destination, thereby enabling multipath routing.
When one route to a destination breaks, the source can utilize alternate routes from the route cache,if they are available, to prevent another route discovery.
Similarly, when a link break in a route occurs, the node upstream of the break can perform route salvaging, whereby it utilizes a different route from its route cache, if one is available, to repair the route.
However, even when route salvaging is performed, a RERR message must still be sent to the source to inform it of the break.
Other characteristics that distinguish DSR from other reactive routing protocols include the fact that DSR’s route cache entries need not have lifetimes. Once a route is placed in the route cache, it can remain there until it breaks. However, timeouts, capacity limits, and cache-replacement policies have been shown to improve DSR’s performance
